
0、系统目标
本系统预期目标是构建一个多模态的RAG系统,此系统可实现多种模态的数据导入,包括如PDF、Word、Excel、图片等(仅结构化数据),并可通过对话进行检索,进行整理和返回结果,返回结果和包括图片和文本等。
1、服务端准备
我们这里采用Milvus作为我们的RAG基础,将其在云服务器上事先完成配置,并测试成功进行链接,此处可参考本人的上一章教程,这里不再详细阐述
一文学会云服务器配置Milvus向量数据库 – 今天开始学AI
2、多模态RAG构建
2.1 模型准备
首先我们需要准备我们的词嵌入模型,由于想实现的是一个多模态的RAG,因此需要选择合适的嵌入模型,这里所选择的模型为通用多语言多模态向量模型 — jina-clip-v2,该模型基于 jina-clip-v1 和 jina-embeddings-3 构建,并实现了多项关键改进:
- 性能提升:v2 在文本-图像和文本-文本检索任务中,性能较 v1 提升了 3%。此外,与 v1 类似,v2 的文本编码器也能高效地应用于多语言长文本密集检索索,其性能可与我们目前最先进的模型 —— 参数量低于 1B 的最佳多语言向量模型 jina-embeddings-v3(基于 MTEB 排行榜)—— 相媲美;
- 多语言支持:以 jina-embeddings-v3 作为文本塔,jina-clip-v2 支持 89 种语言的多语言图像检索,并在该任务上的性能相比 nllb-clip-large-siglip 提升了 4%;
- 更高图像分辨率:v2 支持 512×512 像素的输入图像分辨率,相比 v1 的 224×224 有了大幅提升。能够更好地捕捉图像细节,提升特征提取的精度,并更准确地识别细粒度视觉元素;
- 可变维度输出:jina-clip-v2 引入了俄罗斯套娃表示学习(Matryoshka Representation Learning,MRL)技术,只需设置 dimensions 参数,即可获取指定维度的向量输出,且在减少存储成本的同时,保持强大的性能;
这里我们首先安装modelscope库,接着拉取模型即可,注意调整好模型路径(xlm-roberta-flash-implementation可能需要手动转移到.cache/huggingface/modules/transformers_modules/xlm-roberta-flash-implementation内)
pip install modelscope
modelscope download --model jinaai/jina-clip-v2 --local_dir ./jinaai/jina-clip-v2
modelscope download --model jinaai/jina-clip-implementation --local_dir ./jinaai/jina-clip-implementation
modelscope download --model jinaai/jina-embeddings-v3 --local_dir ./jinaai/jina-embeddings-v3
modelscope download --model jinaai/xlm-roberta-flash-implementation --local_dir ./jinaai/xlm-roberta-flash-implementation
2.2 向量数据库构建
这里我们采用Python进行,首先调用pymilvus库,通过connections连接数据库,代码如下
from pymilvus import utility, Collection
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import connections
# 尝试连接到 Milvus 服务器
try:
connections.connect(host='111.6.167.30', port=19530)
print(f"成功连接到 Milvus 服务器,端口为:{19530}")
except Exception as e:
print(f"连接失败:{e}")接着创建两个字段,分别为主键字段和向量字段
- 主键字段 :创建名为 id 的自增主键字段,用于唯一标识每条数据记录,无需手动指定值;
- 向量字段 :定义名为 vector 的浮点向量字段,维度为 1024(模型决定),用于存储文本/图像的嵌入向量;
并设置动态扩展,启用 enable_dynamic_field 特性,允许在插入数据时动态添加未预先定义的字段(如 text 文本内容或 image_url 图片地址);
集合名称设置为multimodal_rag_demo,分片策略设置为shards_num=2,优化数据存储和查询的并发性能,索引类型为IVF_FLAT(基于聚类的倒排索引),其适合大规模数据(百万级以上),通过分簇加速搜索,并将nlist=1024,将数据划分为 1024 个聚类中心,平衡搜索速度与精度,metric_type=COSINE:使用余弦相似度衡量向量间相似性;
collection_name="multimodal_rag_2"
# 定义集合参数
id_field = FieldSchema(
name="id",
dtype=DataType.INT64,
is_primary=True,
auto_id=True
)
vector_field = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
# 创建集合模式(启用动态字段)
schema = CollectionSchema(
fields=[id_field, vector_field],
description="多模态RAG向量存储",
enable_dynamic_field=True # 允许插入额外字段(如text/image_url)
)
# 创建集合
collection = Collection(
name=collection_name,
schema=schema,
shards_num=2
)
# 创建索引
index_params = {
"metric_type": "COSINE",
"index_type":"IVF_FLAT",
"params":{"nlist":1024}
}
collection.create_index(
field_name="vector",
index_params=index_params
)
print("索引创建成功")创建完成后我们可尝试进行数据插入测试,示例如下
# 插入数据(示例数据)
data_to_insert = [
{"text": "示例文本1", "vector": [0.1]*1024},
{"image_url": "http://example.com/img1.jpg", "vector": [0.2]*1024},
# 添加更多数据...
]
try:
insert_result = collection.insert(data_to_insert)
print(f"插入成功,插入行数: {insert_result.insert_count}")
except MilvusException as e:
print(f"插入失败: {e}")
# 加载集合
collection.load()
print("集合加载完成")
# 验证数据
print(f"集合行数: {collection.num_entities}")
3、多模态RAG数据插入
首先下载如下依赖库
pip install transformers torch timm然后通过如下代码,加载嵌入模型并进行实例化,这里定义了词嵌入和图像嵌入的方法
from transformers import AutoModel
from pymilvus import MilvusClient
import torch
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# Define Encoder class to handle text and image embedding generation
class Encoder:
def __init__(self):
# Initialize the model (AutoModel from transformers instead of SentenceTransformer)
# self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
self.model = AutoModel.from_pretrained('./jinaai/jina-clip-v2', trust_remote_code=True)
def encode_text(self, text: list[str]) -> list[float]: # Generate embeddings for text only
with torch.no_grad():
text_emb = self.model.encode_text(text)
return text_emb
def encode_image(self, image_urls: list[str]) -> list[list[float]]:
# Generate embeddings for images only
with torch.no_grad():
image_emb = self.model.encode_image(image_urls)
return image_emb
encoder = Encoder()
数据示例如下,查看嵌入维度是1024
from modelscope import AutoModel
model = AutoModel.from_pretrained('./jinaai/jina-clip-v2', trust_remote_code=True)
sentences = ['A blue cat', 'A red cat', 'A red cat generated by AI', 'A dog biting on a stick']
image_urls = [
'https://www.helloimg.com/i/2025/04/27/680db7185383b.png',
'https://www.helloimg.com/i/2025/04/27/680db74bacdb7.png'
]
# Generate embeddings for text and images
text_embeddings = encoder.encode_text(sentences)
image_embeddings = encoder.encode_image(image_urls)
# Ensure consistent dimensions
dim = len(image_embeddings[0])执行插入流程如下,流程为先连接上Milvus 服务器再连接multimodal_rag_2,接着对示例数据依次进行文本嵌入,得到其嵌入向量和动态字段,再通过insert方法进行插入数据
from pymilvus import utility, Collection
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import connections
# 尝试连接到 Milvus 服务器
try:
connections.connect(host='111.6.167.30', port=19530)
print(f"成功连接到 Milvus 服务器,端口为:{19530}")
except Exception as e:
print(f"连接失败:{e}")
collection = Collection("multimodal_rag_2")
collection.load()
# 插入数据
data_to_insert = []
# 插入文本嵌入(包含动态字段text)
for idx, txt_emb in enumerate(text_embeddings):
data_to_insert.append({
"vector": txt_emb, # 必填字段(Schema定义)
"text": sentences[idx] # 动态字段(自动添加)
})
# 插入图像嵌入(包含动态字段image_url)
for idx, img_emb in enumerate(image_embeddings):
data_to_insert.append({
"vector": img_emb, # 必填字段(Schema定义)
"image_url": image_urls[idx] # 动态字段(自动添加)
})
try:
# 执行插入操作
insert_result = collection.insert(data_to_insert)
print(f"插入成功!共插入 {insert_result.insert_count} 条数据")
# 显式加载集合(确保可查询)
collection.load()
print(f"集合已加载,当前实体数量: {collection.num_entities}")
except MilvusException as e:
print(f"插入失败: {e}")
print(f"错误代码: {e.code}, 错误信息: {e.message}")
4、嵌入后查询
测试脚本如下,通过连接 Milvus 向量数据库并加载一个多模态模型(Jina-CLIP-V2),分别对输入的图像 URL 和文本查询生成对应的嵌入向量,然后在 Milvus 中执行基于余弦相似度的近邻搜索,检索出与查询内容最相关的图文数据,并对搜索结果进行解析和展示,从而实现一个结合图像与文本的多模态检索系统。
from pymilvus import utility, Collection
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import connections
# 尝试连接到 Milvus 服务器
try:
connections.connect(host='111.6.167.30', port=19530)
print(f"成功连接到 Milvus 服务器,端口为:{19530}")
except Exception as e:
print(f"连接失败:{e}")
from transformers import AutoModel
from pymilvus import MilvusClient
import torch
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# Define Encoder class to handle text and image embedding generation
class Encoder:
def __init__(self):
# Initialize the model (AutoModel from transformers instead of SentenceTransformer)
# self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
self.model = AutoModel.from_pretrained('./jinaai/jina-clip-v2', trust_remote_code=True)
def encode_text(self, text: list[str]) -> list[float]: # Generate embeddings for text only
with torch.no_grad():
text_emb = self.model.encode_text(text)
return text_emb
def encode_image(self, image_urls: list[str]) -> list[list[float]]:
# Generate embeddings for images only
with torch.no_grad():
image_emb = self.model.encode_image(image_urls)
return image_emb
encoder = Encoder()
collection = Collection("multimodal_rag_2")
collection.load()
# 多模态搜索(图像+文本查询组合)
query_image_url = 'https://www.helloimg.com/i/2025/04/27/680db74bacdb7.png'
query_text = "Steap Audio"
# 生成查询嵌入(图像+文本)
query_embedding_image = encoder.encode_image([query_image_url])[0]
query_embedding_text = encoder.encode_text([query_text])[0]
# 定义搜索参数
search_params = {
"metric_type": "COSINE",
"params": {"nprobe": 10} # 仅对IVF类索引有效
}
# 执行图像嵌入搜索
try:
image_search_result = collection.search(
data=[query_embedding_image], # 查询向量
anns_field="vector", # 向量字段名
param=search_params, # 搜索参数
limit=2, # 返回结果数量
output_fields=["text", "image_url"], # 需要返回的动态字段
expr=None # 过滤表达式(可选)
)
except MilvusException as e:
print(f"图像搜索失败: {e}")
image_search_result = []
# 执行文本嵌入搜索
try:
text_search_result = collection.search(
data=[query_embedding_text],
anns_field="vector",
param=search_params,
limit=2,
output_fields=["text", "image_url"]
)
except MilvusException as e:
print(f"文本搜索失败: {e}")
text_search_result = []
# 结果解析函数
def parse_search_result(results, source_type):
parsed = []
for hits in results:
for hit in hits:
item = {
"score": hit.score,
"source": source_type,
"text": hit.entity.get("text"),
"image_url": hit.entity.get("image_url")
}
parsed.append(item)
return parsed
# 解析并合并结果
image_results = parse_search_result(image_search_result, "image_query")
text_results = parse_search_result(text_search_result, "text_query")
# 打印结果(示例格式)
print("图像查询结果:")
for res in image_results:
print(f"来源: {res['source']} | 得分: {res['score']:.4f}")
if res['image_url']: print(f"图片地址: {res['image_url']}")
if res['text']: print(f"关联文本: {res['text']}")
print("-"*40)
print("\n文本查询结果:")
for res in text_results:
print(f"来源: {res['source']} | 得分: {res['score']:.4f}")
if res['image_url']: print(f"图片地址: {res['image_url']}")
if res['text']: print(f"关联文本: {res['text']}")
print("-"*40)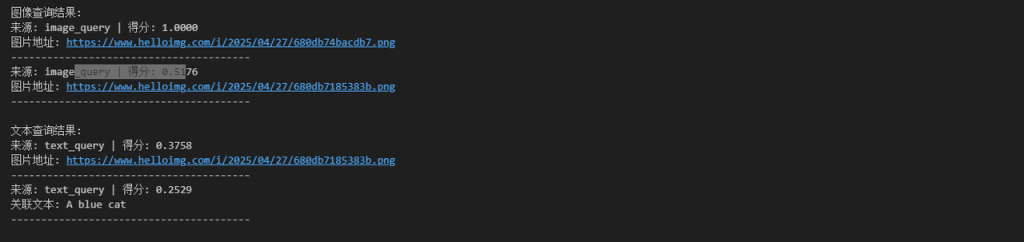
5、服务化使用
5.1 数据插入服务化
首先安装如下依赖库
!pip install langchain-community --user
!pip install langchain --user
!pip install docx2txt
!pip install fastAPI
!pip install pypdf接着直接运行如下脚本,即可通过接口进行调用
该代码实现了一个基于 FastAPI 的多模态 RAG 服务,通过整合 Milvus 向量数据库和 Jina-CLIP-V2 多模态模型,提供了支持文本、图片 URL 和文档文件的上传与向量化接口,并将处理后的文本内容或图片嵌入存入 Milvus 集合中,用于后续的多模态检索应用。
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from transformers import AutoModel
import torch
from pymilvus import Collection, connections
from langchain_community.document_loaders import (
PyPDFLoader,
TextLoader,
Docx2txtLoader,
CSVLoader,
UnstructuredMarkdownLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
import shutil
from tempfile import NamedTemporaryFile
from fastapi import Body
from pydantic import BaseModel
from typing import List
app = FastAPI()
# Milvus配置
MILVUS_HOST = '111.6.167.30'
MILVUS_PORT = 19530
COLLECTION_NAME = "multimodal_rag_2"
# 图片URL接口
class ImageUrls(BaseModel):
urls: List[str]
# 初始化Milvus和模型
@app.on_event("startup")
async def startup():
try:
# 连接Milvus
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
global collection
collection = Collection(COLLECTION_NAME)
collection.load()
# 加载编码模型
global encoder
encoder = AutoModel.from_pretrained(
'./jinaai/jina-clip-v2',
trust_remote_code=True
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"初始化失败: {str(e)}")
# 文档处理函数
def process_document(file_path: str) -> list:
if file_path.endswith(".pdf"):
loader = PyPDFLoader(file_path)
elif file_path.endswith(".txt"):
loader = TextLoader(file_path)
elif file_path.endswith(".docx"):
loader = Docx2txtLoader(file_path)
elif file_path.endswith(".csv"):
loader = CSVLoader(file_path)
elif file_path.endswith(".md"):
loader = UnstructuredMarkdownLoader(file_path)
else:
raise ValueError("不支持的文件类型")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
length_function=len
)
return [doc.page_content for doc in splitter.split_documents(documents)]
# 文件上传接口
@app.post("/upload/file/")
async def upload_file(file: UploadFile = File(...)):
try:
# 保存临时文件
with NamedTemporaryFile(delete=False, suffix=file.filename) as tmp:
shutil.copyfileobj(file.file, tmp)
tmp_path = tmp.name
# 处理文档
texts = process_document(tmp_path)
embeddings = encoder.encode_text(texts).tolist()
# 插入Milvus
data = [
{"vector": emb, "text": text}
for emb, text in zip(embeddings, texts)
]
result = collection.insert(data)
collection.load()
return JSONResponse({
"status": "success",
"inserted": result.insert_count,
"entities": collection.num_entities
})
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
finally:
# 清理临时文件
if os.path.exists(tmp_path):
os.remove(tmp_path)
# 修改图片接口
@app.post("/upload/image-urls/")
async def upload_image_urls(data: ImageUrls): # 使用模型接收
try:
urls = data.urls # 获取列表
embeddings = encoder.encode_image(urls).tolist()
data_to_insert = [
{"vector": emb, "text": url}
for emb, url in zip(embeddings, urls)
]
result = collection.insert(data_to_insert)
collection.load()
return JSONResponse({
"status": "success",
"inserted": result.insert_count,
"entities": collection.num_entities
})
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# 文本接口
@app.post("/upload/text/")
async def upload_text(data: dict = Body(...)): # 修改此处
try:
text = data.get("text") # 从请求体中获取 text
if not text:
raise HTTPException(400, "text 字段不能为空")
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
length_function=len
)
texts = splitter.split_text(text)
embeddings = encoder.encode_text(texts).tolist()
data_to_insert = [
{"vector": emb, "text": txt}
for emb, txt in zip(embeddings, texts)
]
result = collection.insert(data_to_insert)
collection.load()
return JSONResponse({
"status": "success",
"inserted": result.insert_count,
"entities": collection.num_entities
})
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)调用示例如下
import requests
import os
# # 文件上传接口(Python 版)
# def upload_file(file_path):
# url = "http://localhost:8000/upload/file/"
# headers = {"accept": "application/json"}
# # 确保文件存在
# if not os.path.exists(file_path):
# raise FileNotFoundError(f"文件 {file_path} 不存在")
# # 发送请求
# with open(file_path, "rb") as f:
# files = {"file": f}
# response = requests.post(
# url,
# headers=headers,
# files=files
# )
# # 处理响应
# if response.ok:
# print("上传成功:", response.json())
# else:
# print("上传失败:", response.status_code, response.text)
# # 使用示例
# upload_file("公众号推文2.pdf")
def upload_image_urls(urls):
url = "http://localhost:8000/upload/image-urls/"
headers = {"Content-Type": "application/json"}
data = {"urls": urls} # urls 需是列表
response = requests.post(url, json=data, headers=headers)
if response.ok:
print(f"成功插入 {response.json()['inserted']} 张图片向量")
print(f"当前总实体数:{response.json()['entities']}")
else:
print(f"插入失败:{response.status_code}")
print(response.text)
# 使用示例
image_urls = [
"https://www.helloimg.com/i/2025/04/27/680df2fb24e44.png",
"https://www.helloimg.com/i/2025/04/27/680df32016474.png"
]
upload_image_urls(image_urls)
# def upload_text(text):
# url = "http://localhost:8000/upload/text/"
# headers = {"Content-Type": "application/json"}
# # 构造请求体(显式指定字段名)
# data = {"text": text} # 必须与接口定义的字段名一致
# response = requests.post(url, json=data, headers=headers)
# if response.ok:
# print(f"成功插入 {response.json()['inserted']} 个文本块")
# else:
# print(f"插入失败:{response.status_code}")
# print("错误信息:", response.text)
# # 使用示例
# sample_text = "这是需要插入的文本内容"
# upload_text(sample_text) # 确保传递非空文本
5.2 交互智能体构建
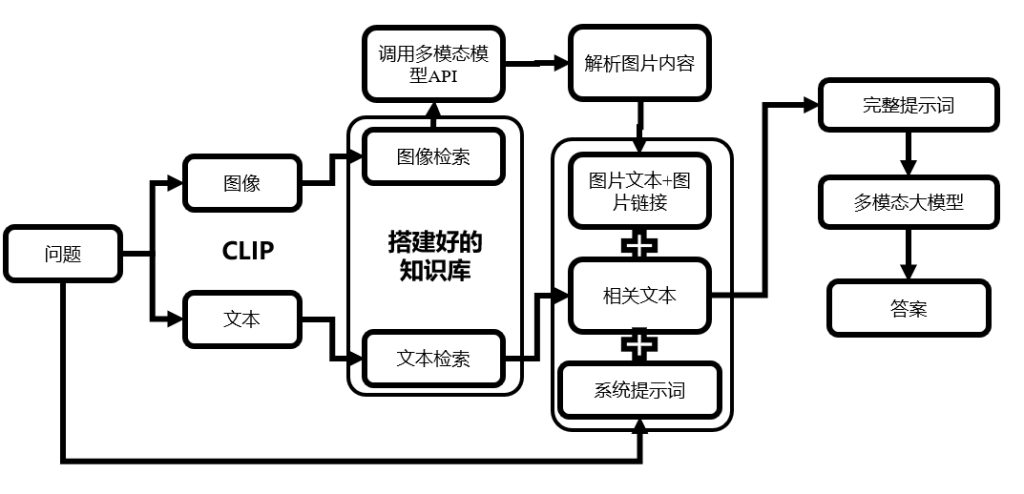
该代码实现了一个基于多模态检索与大模型生成的智能问答系统,通过连接 Milvus 向量数据库和使用 Jina-CLIP-V2 多模态编码器,结合 DashScope 的 Qwen-VL-Plus 多模态大模型,完成对用户文本或图像查询的语义搜索、相关图文内容召回、图像内容解析,并最终由大模型生成结构化回答,实现了从查询到结果生成的端到端多模态 RAG(Retrieval-Augmented Generation)流程。
import json
from pymilvus import Collection, MilvusException
from pymilvus import connections
from transformers import AutoModel
import torch
import os
from openai import OpenAI
import requests
from urllib.parse import urlparse
# 连接Milvus服务器
try:
connections.connect(host='111.6.167.30', port=19530)
print(f"成功连接到 Milvus 服务器,端口为:{19530}")
except Exception as e:
print(f"连接失败:{e}")
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
class Encoder:
def __init__(self):
self.model = AutoModel.from_pretrained(
'./jinaai/jina-clip-v2',
trust_remote_code=True
)
def encode_text(self, texts: list[str]) -> list[float]:
with torch.no_grad():
return self.model.encode_text(texts).tolist()
def encode_image(self, image_urls: list[str]) -> list[float]:
with torch.no_grad():
return self.model.encode_image(image_urls).tolist()
encoder = Encoder()
collection = Collection("multimodal_rag_2")
collection.load()
# 初始化OpenAI客户端
client = OpenAI(
api_key="sk-7cc2531e8b3c425e803eed8296b5072d",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def is_valid_url(url):
try:
headers = {'User-Agent': 'Mozilla/5.0'} # 添加UA避免被拦截
response = requests.head(url, headers=headers, timeout=5, allow_redirects=True)
content_type = response.headers.get('Content-Type', '')
return response.status_code == 200 and content_type.startswith('image/')
except requests.RequestException:
return False
class FinancialAssistant:
def __init__(self, encoder, collection):
self.encoder = encoder
self.collection = collection
# 多模态提取图片信息
def extract_image_info(self, image_urls):
system_image_prompt = """
你是一个图片解析助手,用户会向你提供一张或者多张图片,请根据图片内容进行,尽可能的进行描述
你需要根据图片内容生成简洁的描述,描述中需要包含图片的主要元素和特征。
返回json格式,包含以下字段:
[
{{
"text": 图片的描述信息,
"images": 图像URL
}},
// 其他条目...
]
"""
user_content = []
valid_urls = []
for image_url in image_urls:
if is_valid_url(image_url):
valid_urls.append(image_url)
# 修正:分两次添加元素
user_content.append(
{"type": "text", "text": f"这张图片url是{image_url}"}
)
user_content.append(
{"type": "image_url", "image_url": {"url": image_url}}
)
print(f"有效的图像URL: {image_url}")
else:
print(f"无效的图像URL: {image_url}")
if not valid_urls:
return []
messages = [
{"role": "system", "content": system_image_prompt},
{"role": "user", "content": user_content}
]
try:
completion = client.chat.completions.create(
model="qwen-vl-plus",
messages=messages
)
# print(completion)
return completion.choices[0].message.content
except Exception as e:
print(f"图片解析失败: {e}")
return []
def search_and_respond(self, query_text=None, query_image_url=None):
results = []
images_urls = []
text_images_urls=[]
valid_urls = set()
image_results = []
text_images_results = []
# 图像查询
if query_image_url and is_valid_url(query_image_url):
image_embedding = self.encoder.encode_image([query_image_url])[0]
image_params = {
"metric_type": "COSINE",
"params": {"nprobe": 10},
"expr": "text like 'http%'" # 过滤非URL内容
}
try:
image_res = self.collection.search(
data=[image_embedding],
anns_field="vector",
param=image_params,
limit=3,
output_fields=["text"]
)
images_urls.extend([
{"type": "image", "content": hit.entity.get("text")}
for hits in image_res for hit in hits
])
except MilvusException as e:
print(f"图像搜索失败: {e}")
# 文本查询(也可查询出图像)
if query_text:
text_embedding = self.encoder.encode_text([query_text])[0]
text_params = {
"metric_type": "COSINE",
"params": {"nprobe": 10}
}
try:
text_res = self.collection.search(
data=[text_embedding],
anns_field="vector",
param=text_params,
limit=5,
output_fields=["text"]
)
text_images_urls.extend([
{"type": "text", "content": hit.entity.get("text")}
if not hit.entity.get("text").startswith(('http', 'https'))
else {"type": "image", "content": hit.entity.get("text")}
for hits in text_res for hit in hits
])
except MilvusException as e:
print(f"文本搜索失败: {e}")
# 处理图像搜索结果
if images_urls:
image_results = self.extract_image_info(images_urls)
print("图搜图片检索内容提取----------------------------------")
print(image_results)
print("----------------------------------------------------")
# 处理文本种图像搜索结果字段
if text_images_urls:
for item in text_images_urls:
if item["type"] == "image":
text_images_results.append(self.extract_image_info([item["content"]]))
else:
results.append({
"type": "text",
"content": item["content"]
})
print("文搜图片检索内容提取----------------------------------")
print(text_images_results)
print("----------------------------------------------------")
# 构造API请求(新增系统设定)
rag_content = []
# 添加搜索结果到用户内容
for item in results:
if item["type"] == "image":
if is_valid_url(item["content"]) and item["content"] not in valid_urls:
rag_content.append({
"type": "image_url",
"image_url": {"url": item["content"]}
})
valid_urls.add(item["content"])
else:
rag_content.append({
"type": "text",
"text": item["content"]
})
rag_content.extend(text_images_results)
rag_content.extend(image_results)
print(f"RAG内容: {rag_content}")
print("----------------------------------------------------")
system_prompt = """
你是一个智能助手,用户会向你提问。请根据用户的问题和提供的参考信息进行回答。
你需要过滤与问题无关的信息,针对用户的核心问题提供简洁的回答。
请注意,用户可能会提供图像或文本作为参考信息,其中图像部分每个均会有URL及其相关描述。
你需要根据这些信息来生成回答,注意观察如果参考信息内多个图片url完全一样,那仅回复其中一个即可。
回答方式需要保证足够简洁和准确。
你可以使用提供的参考信息来增强你的回答,但请确保回答的核心是用户的问题。
回答格式为json,包含以下字段:
{
"text":针对用户问题的回答,与用户交互的文本信息,
"images": [图像URL列表],
}
"""
# 构造用户消息
user_content = f""""
你的设定是:{system_prompt}\n
当前用户问题为:{query_text}\n
参考信息为:{str(rag_content)}
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content}
]
# 调用OpenAI API
try:
print(f"请求消息: {messages}")
print("----------------------------------------------------")
response = client.chat.completions.create(
model="qwen-vl-plus",
messages=messages
)
return response
except Exception as e:
print(f"API调用失败: {e}")
return None
# 使用示例
assistant = FinancialAssistant(encoder, collection)
response = assistant.search_and_respond(
query_text="蓝色头发少女有吗?",
)
# print(response.choices[0].message.content)
result = response.choices[0].message.content
json_result=json.loads(result)
print(json_result.get("text"))
print(json_result.get("images"))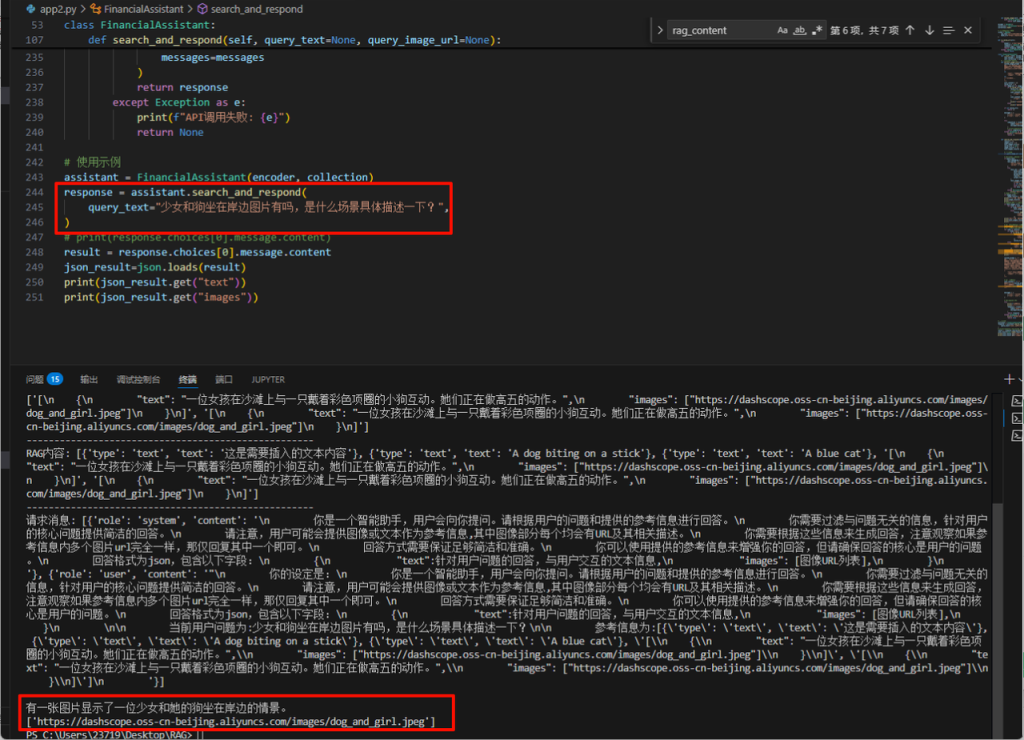


太棒了!!!!!太强了!!!!太帅了!!!!啊啊啊啊啊啊啊