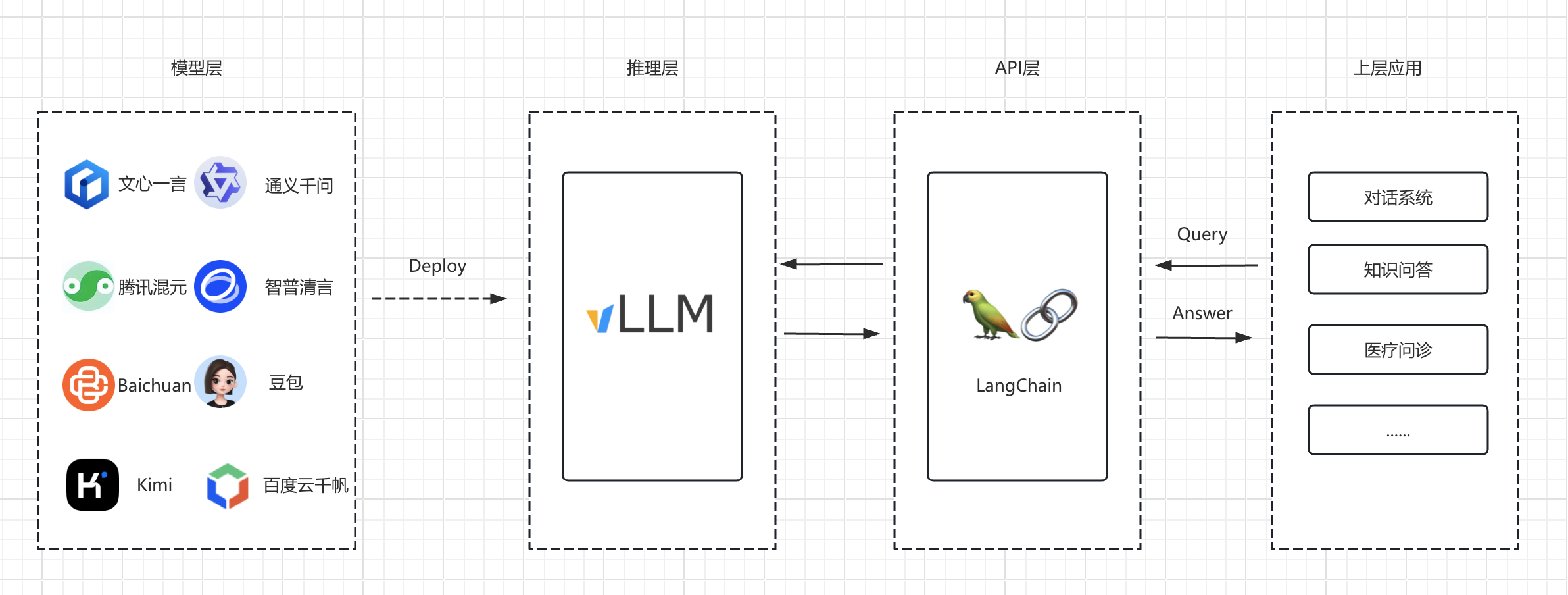
基础介绍
Ollama介绍
轻量级本地化工具,专为个人开发者和小规模实验设计,主打快速部署和低资源占用
核心优势:
- 一键安装,支持跨平台(Windows/macOS/Linux),无需编程基础即可使用;
- 内置1700+预训练模型,自动下载int4量化版本,显存占用极低(如Qwen2.5-14B仅需11GB显存);
- 支持CPU/GPU混合运行,空闲时自动释放显存,适合低配置设备(如16GB内存笔记本);
- 提供类ChatGPT的交互式命令行界面,适合快速测试和原型开发;
局限性:
- 并发力弱(单次请求响应快,但吞吐量低),无法处理高并发任务;
- 量化模型可能降低生成质量(如逻辑严谨性或创意性下降);
VLLM介绍
生产级推理框架,专注企业级高并发场景,强调吞吐量和稳定性
核心优势:
- 基于PagedAttention技术优化显存管理,支持动态批处理,千级并发吞吐量是Ollama的24倍;
- 使用原始FP16/BF16模型,生成质量高,支持HuggingFace格式模型和分布式部署;
- 兼容OpenAI API接口,可直接替换企业现有AI服务,无缝集成业务系统;
局限性:
- 必须依赖NVIDIA GPU(如A100/H100),显存占用高;
- 部署相对复杂,需手动配置Python/CUDA环境,技术门槛较高;
二者对比
Ollama是“个人实验利器”,vLLM是“企业生产引擎”。若需兼顾两者,可先用Ollama本地验证模型,再用vLLM部署生产环境。
| 对比维度 | Ollama | vLLM |
|---|---|---|
| 核心场景 | 个人学习、本地测试 | 企业级API服务、高并发推理 |
| 硬件要求 | CPU可用,GPU可选 | 必须NVIDIA GPU |
| 显存占用 | 极低(量化模型有压缩) | 极高(原始模型占用完整显存) |
| 单次推理速度 | 更快(Qwen2.5-7B约3秒) | 稍慢(Qwen2.5-7B约3.5-4.3秒) |
| 并发吞吐量 | 低(单线程为主) | 极高(动态批处理,支持并发) |
| 模型支持 | 内置1700+量化模型,开箱即用 | 需手动下载原始模型 |
| 部署难度 | 一键安装,无需技术背景 | 需配置环境,依赖经验 |
| 交互方式 | 命令行对话界面 | 仅API调用(无交互界面) |
| 扩展性 | 单机部署,多GPU支持有限 | 支持分布式部署、多GPU并行 |
| 典型用途 | 写代码、翻译、生成文案 | 构建智能客服、批量数据分析 |
| 资源管理 | 空闲时释放显存,动态调整资源 | 显存固定分配,需预留峰值资源 |
环境准备
大模型部署所需要的算力一般比较高,我们需要根据自己所部署的模型进行环境的准备,本次我们选择的模型是DeepSeek-R1-Distill-Qwen-32B-AWQ量化版本,两张A100 40G卡足够
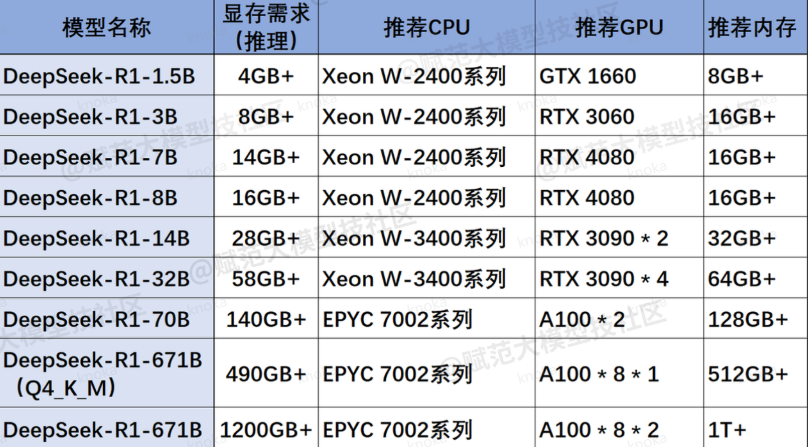
这里我选择用两张A100 40G进行模型的部署,通过nvitop可以实现实时查看设备的配置信息变化

环境配置
使用VLLM部署模型,那么首先就是要安装VLLM,这里安装可直接使用pip
pip install vllm -i https://repo.huaweicloud.com/repository/pypi/simple之后就是配置模型下载功能,这里我们可以从ModelScope平台进行模型的下载,也可以从hugging face进行模型下载,相对应的,选择哪个平台就要配置那个平台的下载功能,这里我们选择ModelScope
pip install modelscope -i https://repo.huaweicloud.com/repository/pypi/simple模型选择
前面已经配置好我们的模型下载服务,那么接下来就是要进行模型的下载,可以先在ModelScope平台进行模型的查找:https://modelscope.cn/models
下载指令如下,这里我只用了两张A100,因此为保证对话长度,选择使用AWQ量化版本
modelscope download --model Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ --local_dir ./DeepSeek-R1-Distill-Qwen-32B
# modelscope download deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir ./DeepSeek-R1-Distill-Qwen-14B
# modelscope download --model Qwen/QwQ-32B-AWQ --local_dir ./QwQ-32B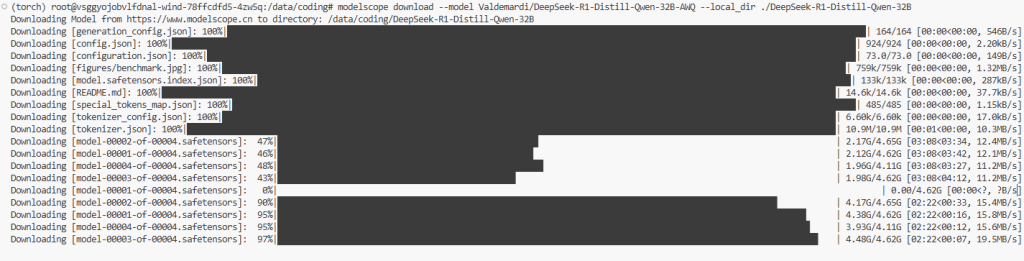
服务启动
对话模型
模型部署
启动命令如下,注意如果你使用的是Tesla V100-SXM2-32GB卡的话,因其计算能力(Compute Capability 7.0)不支持bfloat16数据类型,而vLLM默认尝试使用bfloat16,但该数据类型需要至少支持Compute Capability 8.0的GPU(如A100/A800等),因此需修改启动参数,显式指定使用float16/half精度
这里我用的卡是双卡A100,可直接进行启动,VLLM会自动判别模型是什么类型的,如是否为AWQ量化,因此这里我们无需再次指定,参数介绍如下,也可去阅读官方文档:Engine Arguments — vLLM
| 参数 | 说明 | 可选值/示例 | 备注 |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | 加载的模型名称 | 自定义模型路径 | 需确保模型文件存在且与vLLM兼容 |
| –host 0.0.0.0 | 服务器监听的IP地址 | 0.0.0.0或127.0.0.1 | 0.0.0.0允许外部访问 |
| –port 30041 | 服务监听的端口号 | 1-65535 | 需确保端口未被占用且有访问权限 |
| –uvicorn-log-level info | 控制Uvicorn服务器的日志级别 | debug, info, warning, error | 设置为info时输出基本运行信息,调试时可设为debug |
| –pipeline-parallel-size 1 | 流水线并行度(多GPU间层拆分) | ≥1 | 通常为1(禁用流水线并行),仅当模型支持且GPU数量足够时调整 |
| –tensor-parallel-size 4 | 张量并行度(单层内参数拆分到多GPU) | ≥1 | 需与可用GPU数量匹配(如设置为4需至少4块GPU) |
| –gpu-memory-utilization 0.9 | GPU显存利用率上限 | 0.0-1.0 | 设置为0.9时允许显存占用不超过90%,避免OOM错误 |
| –device cuda | 指定运行设备 | cuda(GPU)或cpu | 需已安装CUDA驱动且硬件支持 |
| –enable-prefix-caching | 启用前缀缓存加速生成 | 无 | 对重复前缀的输入(如聊天历史)可显著提升推理速度 |
| –trust-remote-code | 信任远程代码(如加载自定义模型代码) | 无 | 加载HuggingFace社区模型时可能需要此参数 |
| –max-model-len 65536 | 模型支持的最大上下文长度 | 根据模型和硬件调整 | 超过模型原生支持长度时可能影响效果 |
| –api-key XnZ9qP7L… | API访问密钥(身份验证) | 自定义字符串 | 需在请求时通过Header传递相同密钥(如Authorization: Bearer XnZ9qP7L…) |
| –enable-reasoning | 启用推理模式(可能关联中间步骤输出或特定逻辑) | 无 | 需模型支持(如DeepSeek-R1可能内置推理增强功能) |
| –reasoning-parser deepseek_r1 | 指定推理结果的解析器 | 模型相关值(如deepseek_r1) | 需与模型配套使用,可能用于结构化输出(如思维链、工具调用等) |
vllm serve DeepSeek-R1-Distill-Qwen-32B --host 0.0.0.0 --port 30041 --uvicorn-log-level info --pipeline-parallel-size 1 --tensor-parallel-size 2 --gpu-memory-utilization 0.9 --device cuda --enable-prefix-caching --trust-remote-code --max-model-len 131072 --api-key 你的密钥 --enable-reasoning --reasoning-parser deepseek_r1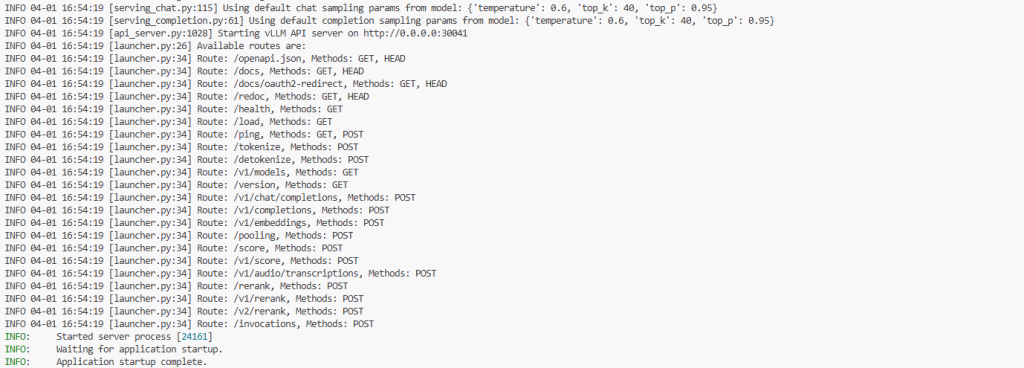
模型测试-Postman
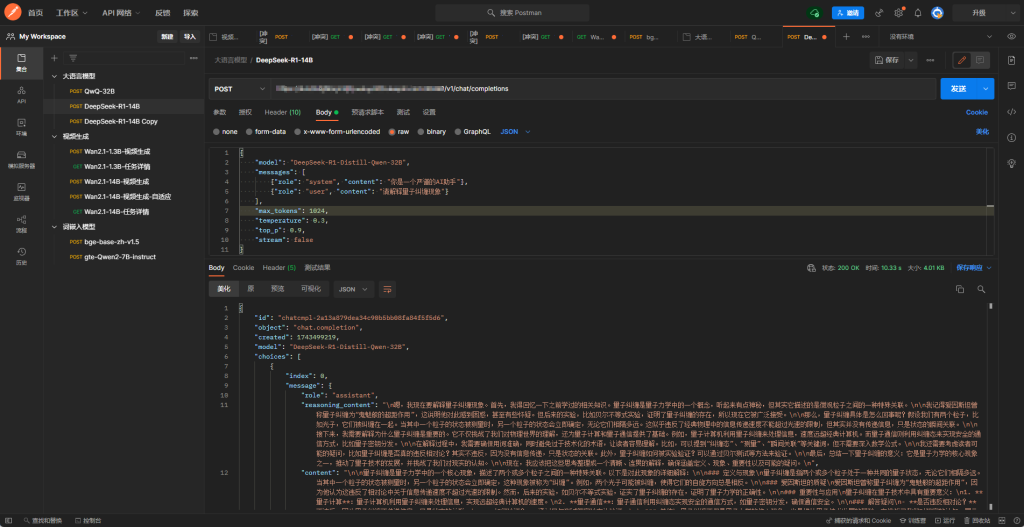
请求配置如下:Method: POST URL: http://IP地址:端口/v1/chat/completions
Headers
| Key | Value |
|---|---|
| Content-Type | application/json |
| Authorization | Bearer 启动时候的密钥 |
Request Body (JSON)
{
"model": "QwQ-32B",
"messages": [
{"role": "system", "content": "你是一个严谨的AI助手"},
{"role": "user", "content": "请解释量子纠缠现象"}
],
"max_tokens": 512,
"temperature": 0.3,
"top_p": 0.9,
"reasoning": true,
"reasoning_parser": "deepseek_r1",
"stream": false
}
OpenAI python测试
from openai import OpenAI
client = OpenAI(
api_key="你的密钥",
base_url="http://IP地址:端口/v1"
)
msg = "你好?"
messages = [{"role": "user", "content": msg}]
response = client.chat.completions.create(
model="DeepSeek-R1-Distill-Qwen-32B",
messages=messages,
stream=True,
stream_options={"include_usage": True} # 修正参数名中的下划线
)
reasoning_content = ""
content = ""
for chunk in response:
# 先检查是否存在有效的choices
if not chunk.choices or len(chunk.choices) == 0:
continue # 跳过空choices的chunk
delta = chunk.choices[0].delta
# 处理reasoning_content
if hasattr(delta, "reasoning_content") and delta.reasoning_content:
reasoning_content += delta.reasoning_content
print(f"{delta.reasoning_content}", end="", flush=True)
# 处理content
if hasattr(delta, "content") and delta.content:
content += delta.content
print(f"{delta.content}", end="", flush=True)
# 可选:添加最终换行
print()
词嵌入模型
仅需要添加-task embed参数即可,示例如下
| 参数 | 描述 | 示例/值 | 备注 |
|---|---|---|---|
| bge-base-zh-v1.5 | 要加载的模型名称 | 必填 | 中文文本嵌入模型,支持中英双语 |
| –host | API 服务绑定的主机地址 | 0.0.0.0 | 0.0.0.0 表示允许外部访问 |
| –port | API 服务监听的端口号 | 30049 | 自定义端口需确保未被占用 |
| –gpu-memory-utilization | GPU 显存利用率目标(0.0-1.0) | 0.9 | 0.9 表示使用 90% 的可用显存 |
| –uvicorn-log-level | 控制 Uvicorn 服务器的日志输出级别 | info | 可选值:debug, info, warning, error, critical |
| –dtype | 模型权重数据类型 | float16 | 半精度浮点,可减少显存占用 |
| –task | 指定服务任务类型 | embed | 表示提供嵌入生成服务 |
| –api-key | API 访问密钥(可选安全验证) | 自定义字符串 | 需要客户端在请求头中携带此密钥 |
vllm serve bge-base-zh-v1.5 --host 0.0.0.0 --port 30049 --gpu-memory-utilization 0.9 --uvicorn-log-level info --dtype float16 --task embed --api-key 你的密钥
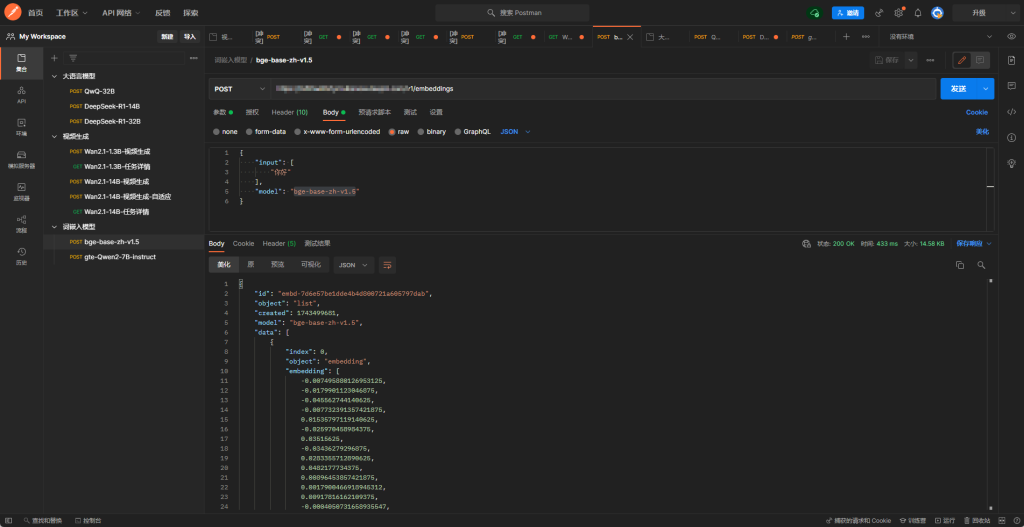
模型测试-Postman
请求配置如下:Method: POST URL: http://IP地址:端口/v1/chat/completions
Headers
| Key | Value |
|---|---|
| Content-Type | application/json |
| Authorization | Bearer 启动时候的密钥 |
{
"input": [
"你好"
],
"model": "bge-base-zh-v1.5"
}
OpenAI Python测试
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "你的密钥"
openai_api_base = "http://IP地址:端口/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
responses = client.embeddings.create(
input=[
"Hello my name is",
"The best thing about vLLM is that it supports many different models"
],
model=model,
)
for data in responses.data:
print(data.embedding)